动态规划方法用来解决强化学习中的规划问题(planning)。规划是指已知状态空间、行为空间、奖励函数与状态转移矩阵(即已知MDP模型)的情况下,判断一个给定策略的价值函数,或判断一个策略的优劣,并找到最优的策略和最优的价值函数。
动态规划方法将一个复杂的问题拆分为若干个子问题,通过求解子问题得到整个问题的解。当问题具有如下的两个性质时,可以采用动态规划的方法:
- 一个复杂问题的最优解由数个小问题的最优解构成,可以通过寻找子问题的最优解来得到复杂问题的最优解。
- 子问题在复杂问题内重复出现,使得子问题的解可以被存储起来重复利用。
MDP满足上述两个性质,贝尔曼方程把问题递归为求解子问题,价值函数相当于存储了一些子问题的解,可以复用。因此可以使用动态规划来求解马尔科夫决策过程。
预测和控制是规划的两个重要内容。预测是对给定策略的评估过程,控制是寻找一个最优策略的过程。
策略评估
策略评估(Policy Evaluation),是指给定一个策略,计算其价值函数。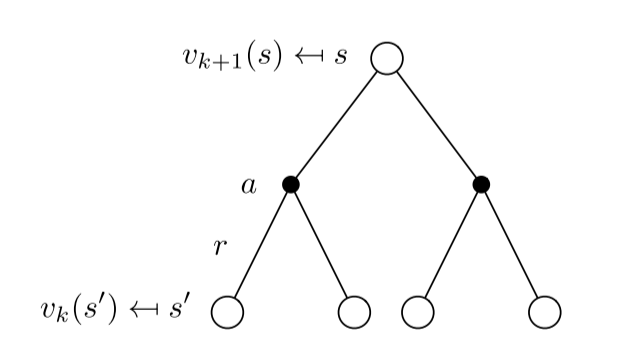
由之前所推导的贝尔曼期望方程可知:
在已知MDP模型的情况下,上式中只有价值函数的值是未知的,因此可以采用自举的方式(bootstrapping),从一个任意一个状态价值函数开始,迭代更新,得到新的状态价值函数,最终收敛。在同步迭代法中,我们使用上一个迭代周期k内的后续状态价值来计算更新当前迭代周期k+1内某状态s的价值:
不断迭代至最终状态函数收敛(即变化的大小低于某个阈值)。
这里举一个简单的例子来看看什么是策略评估:
上面这个方格,灰色部分是起点和终点,其他有1-14共14个状态,在这14个状态每走一步会带来-1的即时奖励,若碰壁则保留在原地不动(仍有-1的即时奖励)。行为集合为上下左右(不能斜着走),每次只能移动一个单位的步长,设折扣因子为(discount factor)为1(即考虑当前和未来的奖励影响权重相同),采取均一概率的随即策略(即上下左右方向概率相同,均为0.25)。策略评估的目的在于,在若干次迭代后,评估这个策略在每个状态下的价值:
可以看到,在没有迭代时,每个状态的价值都是0,代表着agent对这个环境没有任何的认知,在第一次迭代过后(k=1),因为采取均一随机策略,agent对于每个状态的评估都是相同的(以1号方格为例):
在第二次迭代时(k=2),同样以1号方格为例子:
通过上述的方法不断地进行策略迭代中的策略评估,直至最终价值函数收敛,停止迭代:
策略优化
当给定一个策略$\pi$时,可以得到基于该策略的价值函数$v_\pi$,基于产生的价值函数可以得到一个贪婪策略:
依据新的策略$\pi^\prime$往往会产生一个新的价值函数并随之有新的贪婪策略,如此重复循环迭代将最终得到最有价值函数$v_$和最优策略$\pi^$,策略评估和策略优化共同构成了策略迭代(policy iteration),如下图: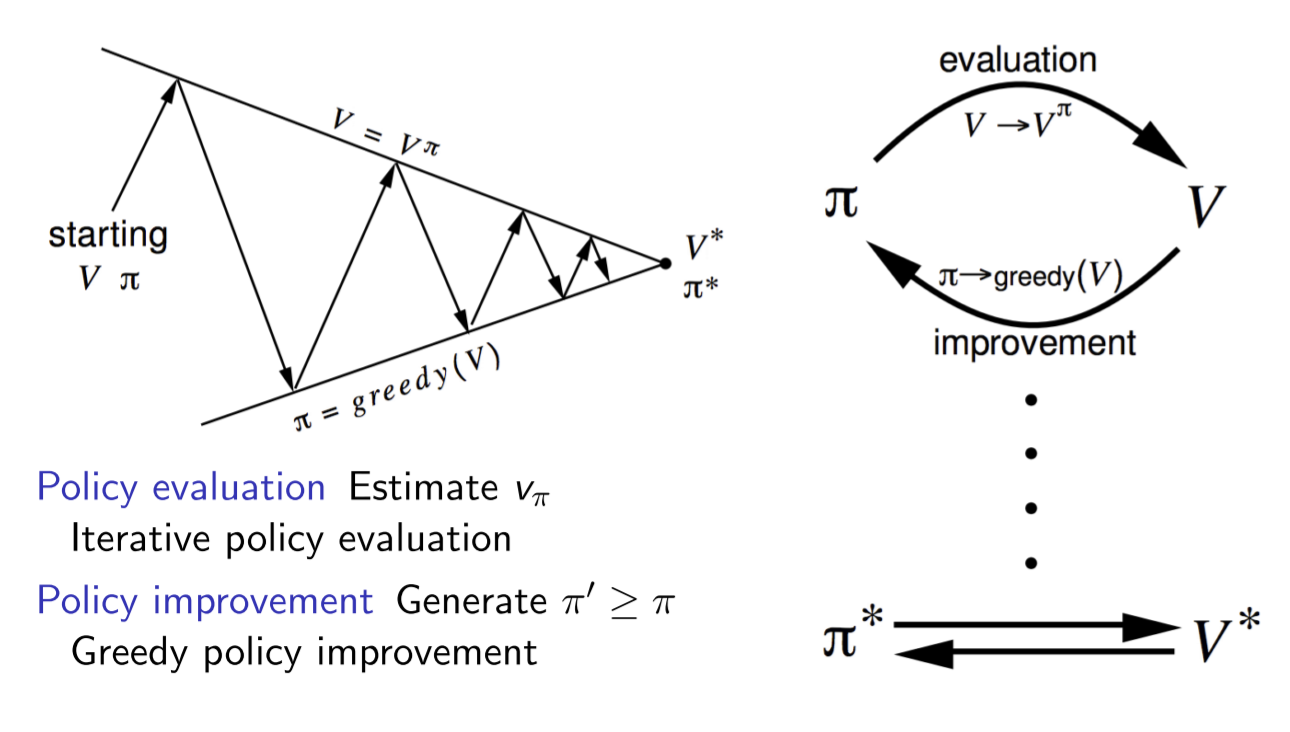
总的来说,从一个初始策略$\pi$和初始价值函数$v$开始,基于该策略进行完整的价值评估过程得到一个新的价值函数,随后依据新的价值函数得到新的贪婪策略,随后计算新的贪婪策略下的价值函数,整个过程反复进行,在这个循环过程中策略和价值函数均得到迭代更新,并最终收敛值最优价值函数和最优策略。除初始策略外,迭代中的策略均是依据价值函数的贪婪策略。
价值迭代
任何一个最优策略可以分为两个阶段,首先该策略要能产生当前状态下的最优行为,其次对于该最优行为到达的后续状态时该策略仍然是一个最优策略。相反的,如果一个策略不能在当前状态下产生一个最优行为,或者这个策略在针对当前状态的后续状态时不能产生一个最优行为,那么这个策略就不是最优策略。联系价值函数可知,一个策略能够获得某状态$s$的最优价值当且仅当该策略也同时获得状态$s$所有可能的后续状态$s^\prime$的最优价值。
一个状态的最有价值,可由其后续状态的最有价值通过贝尔曼最优化方程求解:
这个公式带给我们的直觉是如果我们能知道最终状态的价值和相关奖励,可以直接计算得到最终状态的前一个所有可能状态的最优价值。下面来举一个例子: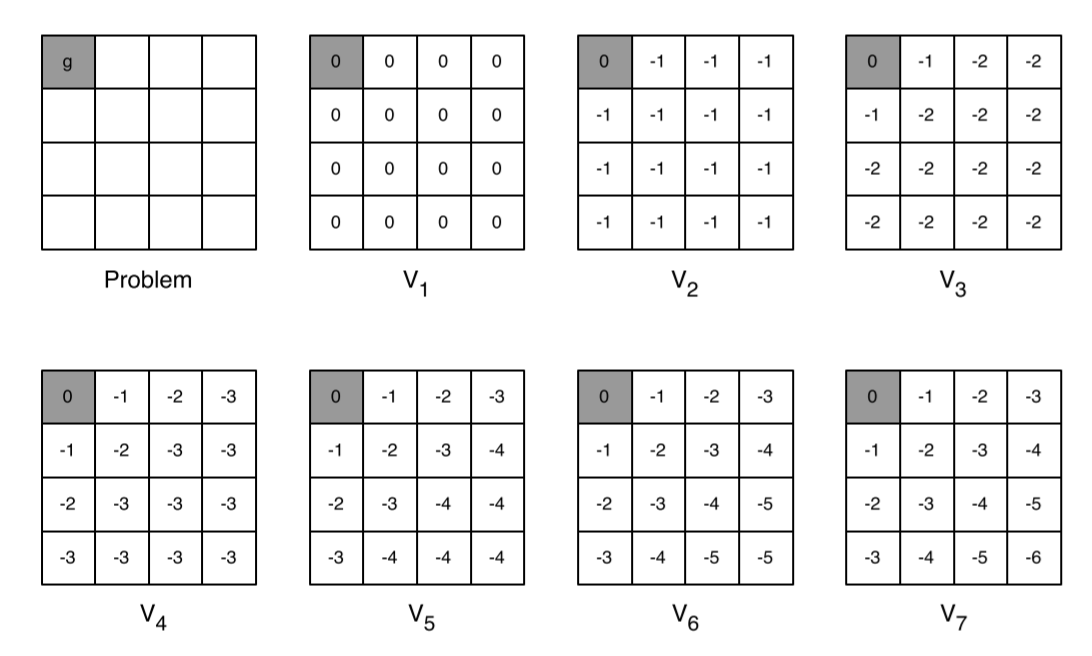
该例为在一个4x4的方格世界寻找最短路径,规则与之前相同,但此时只有左上角是终止状态,假设agent一开始并不知道终点的具体位置,所以需要对所有的状态进行价值迭代。在最初(k=1时),设全部状态的价值都是0,在k=2时,除了左上角的状态,其余都不在终止状态,所以移步后即时奖励均为-1,再加上之前的0价值,所以全部更新为了-1;k=3时,除了与终止状态相邻的两个状态,其余均不能在移步后到达终止状态,所以价值更新结果是$\max(-1,-1)-1=-2$,而对于与终止状态相邻的两个状态来讲,他们的移步后的价值均为0,所以价值更新结果为$\max(-1,0)-1=-1$。以此类推一直迭代,到k=7时得到了全部状态的价值。
价值迭代的目标仍然是寻找到一个最优策略,它通过贝尔曼最优方程从前次迭代的价值函数中计算得到当次迭代的价值函数,在这个反复迭代的过程中,并没有一个明确的策略参与,由于使用贝尔曼最优方程进行价值迭代时类似于贪婪地选择了最有行为对应的后续状态的价值,因而价值迭代其实等效于策略迭代中每迭代一次价值函数就更新一次策略的过程。在纯粹的价值迭代寻找最优策略的过程中,迭代过程中产生的状态价值函数不一定对应一个策略。迭代过程中价值函数更新的公式为:
总结
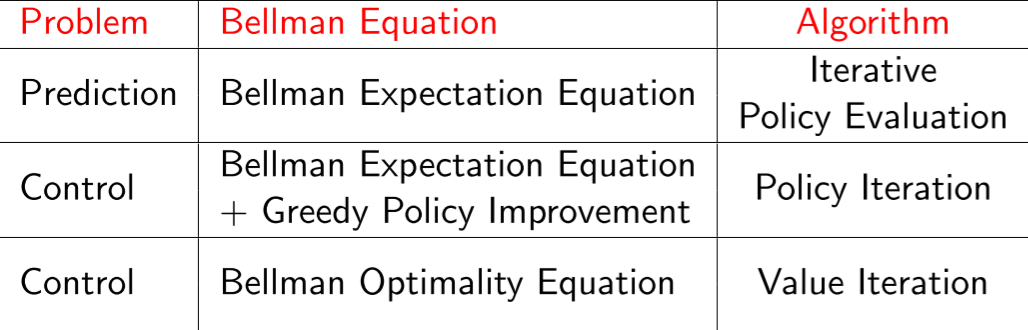
策略迭代分为策略评估加策略更新,其中策略评估是预测问题,采用的是贝尔曼期望方程,策略更新是控制问题,采用的是贝尔曼期望方程和贪心策略;价值迭代是控制问题,采用的是贝尔曼优化方程。
参考资料
- DavidSilver深度强化学习算法第三讲
- 《深入浅出强化学习:原理入门》