概念初探
从小开始,我们就在和环境的互动中学习,我们通过周围环境的反馈来判断我们的行为和选择(统称为决策)是否正确或者合理。将这种思想数学化后,就产生了强化学习,这种方法相比于机器学习中的其他方法,更注重于交互中的学习。用一句话来概括强化学习所解决的问题,就是智能决策问题,更确切的说是序贯决策问题,即需要不断做出决策才能实现目标的问题。
强化学习建立了我们所处的处境和以及我们所采取的行动之间的对应关系,我们以使奖励达到最大化为目的来做出行动。强化学习不同于监督学习,监督学习的过程中,每有一个样本就有一个标签,即我们每做出一个行为就会收到反馈;而强化学习则是在做出一系列行为后,会得到一个反馈值,然后再通过自己的判断来决定这个反馈值的好坏,如果是好的,代表这之前这一系列行为(可能只是某一个或某几个)是有利的,以后在这种对应的处境要多做这类行为,如果是坏的,代表以后要少做这种行为。
The learner is not told which actions to take, but instead must discover which actions yield the most reward by trying them.
同时,一个行为造成的结果(reward)不一定立刻展现出来,并且这个行为会对之后的若干个状态有影响。这就是强化学习的两个重要的特征:
- 奖励延迟(reward delay)
- 试错搜索(trial-and-error search)
强化学习关注全局性,每一个agent都有明确的目标,并且对与环境的改变很敏感,需要应对自己的决策和决策对环境带来的影响之间的关系。
之前我们提到了强化学习解决的是序贯决策问题,在具体介绍之前我们先来回顾一下监督学习:监督学习是解决智能感知问题,拿最常见的手写数字识别(每一个初探神经网络的人的敲门砖)来讲,当给出一个手写数字时,监督学习需要判断出该数字是多少。也就是说,监督学习需要智能体感知出当前的输入具体是什么,感知出是什么才能将其分类。智能感知其实是在学习“输入”长什么样子(特征),以及该长相所对应的是什么(标签)。因此,智能感知必不可少的是输入带有大量标签的数据以供智能体去学习输入的抽象特征与标签的对应关系。
强化学习则不同,序贯决策问题不关心输入长什么样子,只关心在当前输入下应该采用什么动作才能实现最终的目标。当前采用的动作与最终的目标有关。智能体需要解决的是当前采取什么动作才能使整个任务序列达到最优,为了完成这个这个目标,智能体需要不断地和环境进行交互、不断尝试,因为智能体自己在最开始也不知道当前状态下做什么动作最有利于实现目标。
现状与挑战
强化学习中,我们可以把大致的研究问题分为学习(Learning)和计划(Planning)。学习的应用场景是环境是未知的,agent需要和环境做交互,在交互的过程中学习,更新policy;计划的应用场景是环境是已知的,agent只需要不断地学习环境的模型,不需要与环境进行交互。
强化学习中,在探索(exploration)和利用(exploitation)之间的权衡是很关键的任务。为了更好地利用过去经验总结的信息以获取最大的奖励,我们自然要选取当前已知的最优的策略,这就是利用(exploit),然后,为了在未来能够获取更高的奖励,我们又需要不断地开拓和寻找新的未知策略,这就是探索(explore)。在行动有限的前提下,这两者是互相矛盾的。
目前强化学习算法种类繁多,一般可以按照以下几个标准来分类:
- 根据学习算法是否依赖模型分为基于模型的算法(model-based)和无模型的算法(model-free)。共同点是都需要agent和环境进行交互以获取数据,不同点是model-based算法利用交互数据学习环境模型,再基于模型进行序贯决策;model-free则直接利用交互数据改善自身的行为(区别可以理解成model-based借助了一个第三方的工具来进行计算价值函数进而辅助决策)。model-based算法效率更高,但是一般情况下很难建立模型,所以model-free更具有通用性。
- 根据策略的更新和学习方法分为基于值函数的算法(value-based)、基于策略搜索的算法(policy-based)和AC算法(actor-critical)。value-based算法直接学习值函数(value function),最终的策略直接根据值函数贪婪得出,即在任意状态下值函数最大的动作为当前状态下的最优策略;policy-based则是将策略参数化,学习实现目标的最优参数;actor-critical是两者的结合。
- 根据环境返回的回报函数(return signal)是否已知分为正向强化学习和逆向强化学习。回报函数指定的算法称为正向。
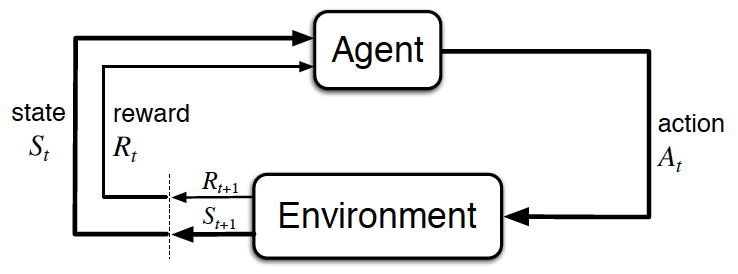
强化学习要素
Beyond the agent and the environment, one can identify four main subelements of a reinforcement learning system: a policy,a reward signal,a value function, and, optionally, a model of the environment.
- 策略(policy):表示在某个状态下的行动。策略可以是确定性的,即和状态绑定,agent在达到某个状态时就直接采取对应的策略;策略也可以是随机性的,在某个状态下,会有不同的策略,分别对应不同的概率。
- 回报函数(reward signal):在agent每走一步时,环境会反馈给其一个reward,在整个过程走完后,agent将每一步的reward相加得到总共的回报(total reward),而强化学习的最终目的就是使自己的行为达到获取最大的回报。同时,reward也可能是随机的,即使时相同的状态相同的行为,每次的reward也可能不同,但是会满足一定的概率分布。
- 价值函数(value function):reward表示每一步的环境反馈,value则是整个过程的奖励,他考量的是这个状态之后可能获得的总奖励,所以尽管有时的即时回报(immediate reward)很小,但是这个状态衍生的value却会很大。value是需要预测的,在强化学习几乎全部的算法都是在计算最好的预测value的方法。
- 环境模型(model of the environment):用于对环境的精确描述。
参考资料
- DavidSilver深度强化学习算法第一讲
- 《深入浅出强化学习:原理与入门》