最近又到了一年一度看《形势与政策》网课的时候了,全国高校,每个专业,无一例外。我校本年度(2020年)选用的是雨课堂的平台。大概有15个视频,每个视频时间20-40分钟不等,观看视频占总分的90%,这些视频全部看一遍,就算开二倍速也要很久,于是自然想到了用自动化脚本自动播放。
网站架构分析
课程地址:https://scut.yuketang.cn/pro/courselist
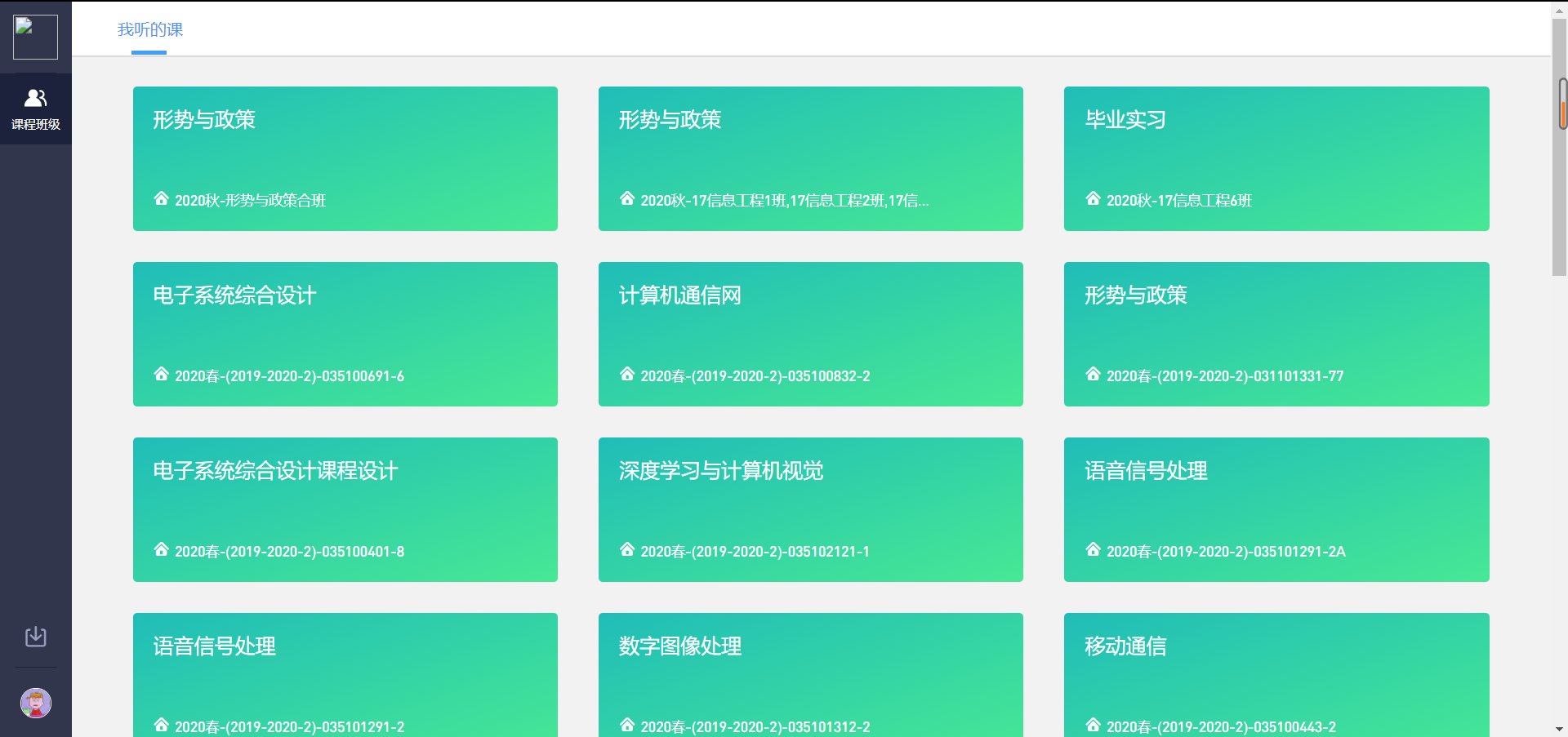
其中第一排第一列的课程就是本学期的《形势与政策》课程。因为我只有这一门课程需要观看,所以我直接点进去,不需要在这个页面获取其他视频的信息。
点击进入《形势与政策》之后:
网址:https://scut.yuketang.cn/pro/lms/7GmGPsM8ci5/4449749/studycontent
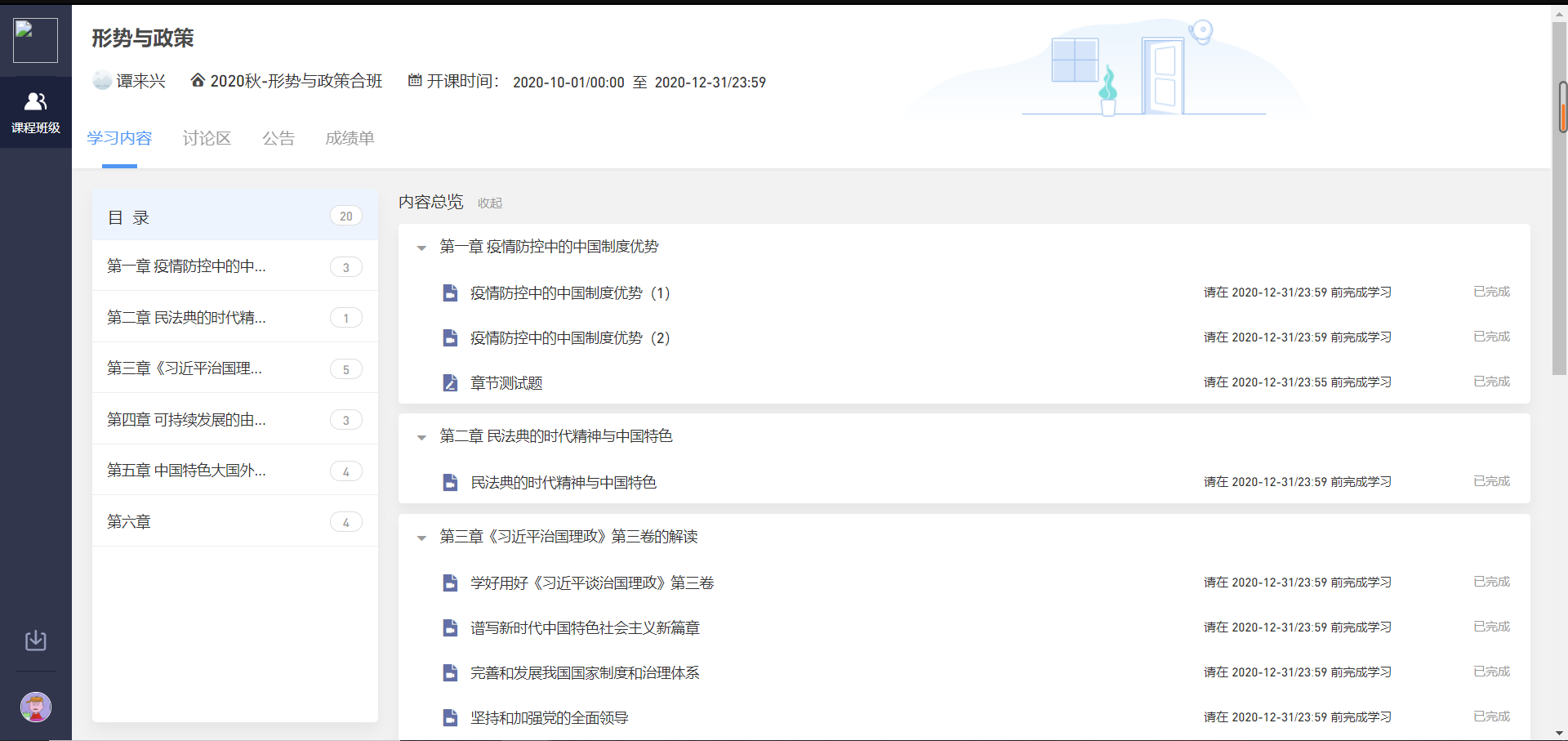
这里的url很明显,“7GmGPsM8ci5”和“4449749”都是一些比较明显的参数,但是目前还不知道代表着什么。
这时我们进入控制台,试图寻找一些有关每个需要观看的视频的参数和规律等等(其实也没有套路,就是经验,具体要找什么也只有试过才知道)。
经过在Network中加载的页面的寻找,我们很容易的能够发现这些信息:
用户id

https://scut.yuketang.cn/edu_admin/get_user_basic_info/?term=latest&uv_id=2627
章节id
在后期模拟播放时没有用到,所以就不展示了。
学校id
学校id会在用户登陆后清晰的显示在url参数上,用户可以直接获取,所以也不需要抓取。
教室id
教室id会在用户登陆并选择课程后清晰的显示在url参数上,用户也可以直接获取,故也不需要特意去抓取。
视频id
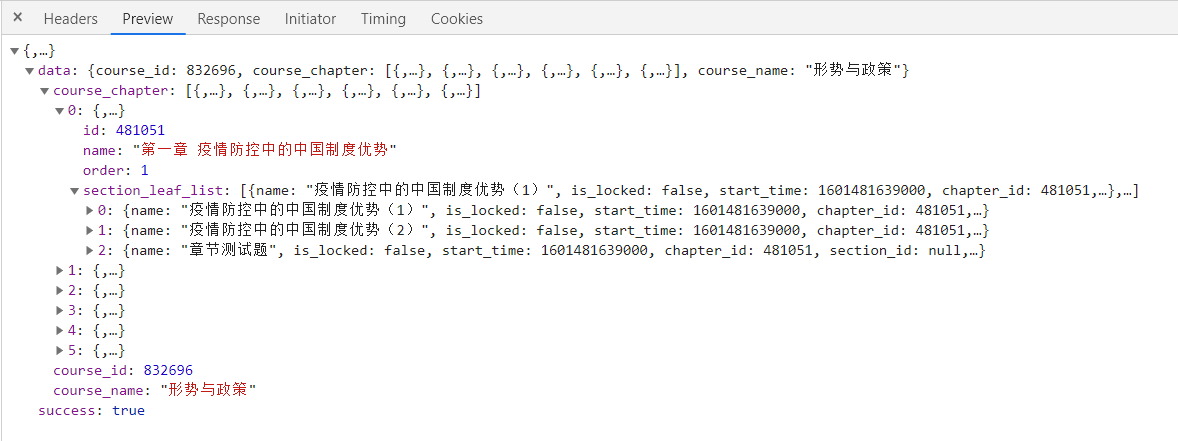
在上面这个网址保存了所有的视频信息,视频名称,视频编号等,具体如下:
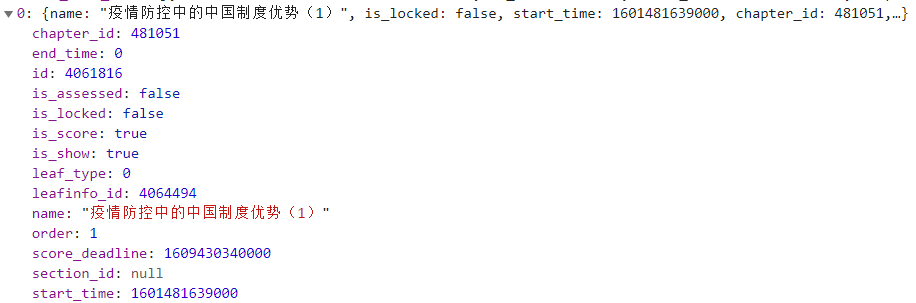
最主要的信息就是id,我是通过率先点开每个视频观察了url的变化,然后再对比发现的,例如我点开第一个视频,网址变为:
https://scut.yuketang.cn/pro/lms/7GmGPsM8ci5/4449749/video/4061816,这里面的参数为教室id+视频id,这样我们就可以将每个视频的id爬取,为了之后的模拟播放做准备。
视频id和用户id抓取
下面给出爬取视频id、用户id等信息的代码:
1 | import requests |
写get_videourl()这个函数主要是因为,访问具体的视频页面在请求头部的referer参数需要对应这个视频网页地址的值。
那么我现在就可以模拟访问每一个视频了。
模拟观看
接下来就是重点了,我现在只是模拟地拿到了每个视频的入口,但是我该如何才能使我的程序自动地播放视频呢?其实熟悉爬虫的朋友们一定对selenium不陌生,这是一个实现网络测试自动化的工具,可以轻松地模拟鼠标的点击,那么自然得也就可以模拟点击播放按钮,然后播放视频,如果能做成多线程,然后再模拟点击二倍速播放,那么就可以在20分钟左右看完所有视频(最长视频时长的1/2)。但是,selenium也有一些不足的地方:
- 容易被识别,很多网站都针对selenium做了反爬虫措施,所以在使用过程中会出现很多小问题(例如前几年常见的自动清空购物车脚本,自动抢货脚本等,现在基本已经被淘宝京东等网站检测到了)。
- 需要安装特定的浏览器驱动,且爬虫速度极慢。
- 缺乏技术含量(😜)。
基于最后一点(以上三点),我基本不使用selenium来进行爬虫。
那么我就要仔细思考一下,服务器到底是如何知道浏览器看了多少进度的视频的(计算机网络知识在脑中打转)。基于经验和资料查找(咨询苏森),以及我人工手动播放了一个视频,并进行了一些操作,如暂停,开始,刷新页面,观看结束等等,我大致有了如下的总结:
浏览器通过POST请求给服务器发送心跳包(heartbeat/),心跳包有对应的类型(‘pause’,‘loadstart’,‘heartbeat’,‘videoend’等等),每个心跳又包含了很多参数,其中便有代表着视频已经播放时间的参数,浏览器不断地给服务器发送心跳包,这就对应着播放视频时进度条的移动,那么我可以模仿整个心跳包的发送过程,以此来”欺骗“服务器我是一个普通浏览器,并且真正地看了视频。
那么先来看看心跳包长什么样:
网址:https://scut.yuketang.cn/video-log/heartbeat/
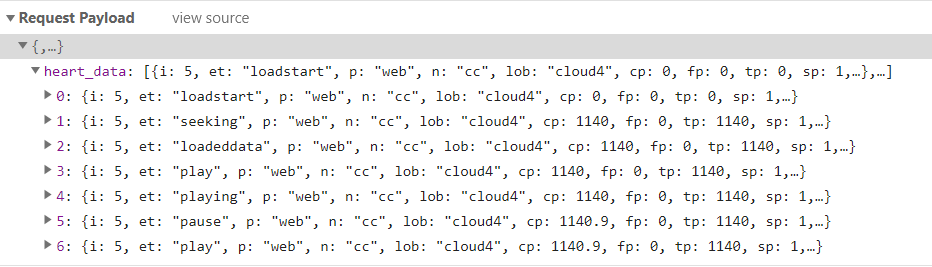
这个需要传给POST请求的data参数的部分是常见的json格式,键为”heart_data“,值为一个列表,列表里面有若干个字典形式的心跳包(上图一个列表里有7个心跳包)。
那么接下来看一下每个心跳包具体有哪些内容:

接下来我来介绍一下经过观察和实验,每个参数的含义:
| 参数 | 含义 |
|---|---|
| c | 课程id(course id) |
| cc | 每个视频的特定参数,在我之前的get_videoid()函数中返回的第二个值即为每个视频的cc值 |
| classroomid | 顾名思义,教室id |
| cp | 视频进度,这是最关键的参数 |
| d | 总时长,也是极其关键的参数 |
| et | 心跳包类型,指明这个心跳包的作用 |
| fp | 不太清楚,固定设为0 |
| i | 固定设置为5 |
| lob | 固定设置为”cloud4“ |
| n | 固定设置为”cc“ |
| p | 固定设置为”web“ |
| pg | 前半段为视频id,后半段为一个下划线+随机字符串(可以只采用一种) |
| skuid | get_videoinfo()函数返回的第一个值即为skuid,每个视频相同 |
| sp | 控制倍速,可选0.5,1, 1.25,1.5,1.75,2等值,不重要,设置为1 |
| sq | 心跳包的序号,顺序加1 |
| t | 固定设置为”video“ |
| tp | 缓存你上一次看的视频进度,不重要,可以每次都设置为0 |
| ts | 1000倍的时间戳,用python的time.time()获取然后乘1000即可 |
| u | 用户id(user_id) |
| uip | 固定设置为”“ |
| v | 视频id(video_id) |
粗体的参数是比较重要的,需要我们调整。这样下来,即使没用完全清楚每一个参数的含义(比如为什么要设为固定的某个值),依然不影响我模拟浏览器观看视频时的发包。接下来就要观察观看视频发送心跳包的流程了。
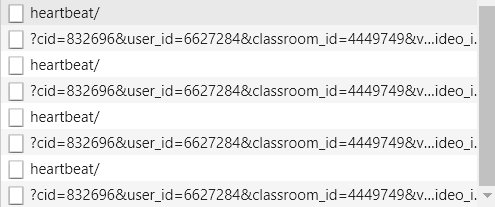
这是我观看视频一段时间的Network发包结果,可以看到,名字为heartbeat/的包就是心跳包,而紧接着的请求是用来查询观看进度,服务器的响应包含了观看进度、观看历史、总时长等信息。而经过观察,每隔30s发送一个heartbeat/请求,而且heartbeat的请求类别从点进视频到播放结束分别为:
空包
loadstart
seeking
loadeddata
play
playing
heartbeat
这时心跳包里的cp参数开始增加,间隔为5s(即每过5s增加一个heartbeat类型的字典,加进列表中),当列表中的元素达到某个阈值,POST发送请求(阈值没有规律,我这里设置为10)。
pause
videoend
下面是描述发包流程的代码:
1 | # 心跳包post请求网址 |
这时发包流程结束,视频看完。
一些问题
- 发包间隔时间
因为正常观看是30s发送一次heartbeat请求,但是这样也很耗费时间,我尝试着不停歇,不断地发送,会出现一些丢包的现象,但是整体没有问题,可以适当停顿1s-5s,以提高发包的成功率。
- 视频总时长
前面提到过,在每个heartbeat/请求后回立刻有一个请求进度的GET请求,这个请求的响应中服务器会返回观看的进度和视频的总时长等信息,一开始我是直接发送这个请求来获得每个视频的时长,但是发现必须是已经有观看记录的视频才可以请求成功,若是未观看的视频则无法请求,除此之外,并没有包含着视频时长的信息。所以这里只能借助cv2模块中的VideoCapture类中的get函数的提取帧速率和帧数的功能,通过请求视频的原始地址结合length = FrameNumber / FramePerSecond来计算视频的时长。
1 | # 获取视频时长 |
- 多线程
本次并未采用多线程,之后会相应的做一些优化。
- 心跳包的请求头
一开始心跳包的POST请求不起作用,经过反复debug,检查到返回的请求状态码为400多,故猜想是请求头的问题,果然是需要在请求头部加上'content-type': 'application/json‘的键值对。
- 答题
刚刚说了,90%的成绩由播放视频产生,还有剩下的10%是由答题产生的,其实和播放视频同理,只要有标准答案,答题也可以以相同的方式发送请求,完成自动答题,这也是以后要完善的一个部分。
写在最后
其实github上有一个郑州大学的师兄写了有关雨课堂的视频自动播放,但是用的是selenium模块,在网上和github上还未找见直接用requests模拟发送请求的自动观看雨课堂的项目。所以这个项目做出来还算有一些成就,然后也给几个同学用了(当然主要是帮美丽可爱的小姐姐😋锻炼自己)。希望自己可以继续完善,做成体系。
代码
1 | import requests |